

Topic Modeling Using LDA and Topic Coherence

Image Created By Author
Introduction
Topic modeling is a powerful technique used in natural language processing to identify topics in a text corpus automatically. Latent Dirichlet Allocation (LDA) is one of the most popular topic modeling techniques, and in this tutorial, we'll explore how to implement it using the Gensim library in Python. Alongside this, we'll touch upon the importance of topic coherence measures, specifically comparing u_mass and c_v, to evaluate the quality of topics generated. We will visualize the coherence values of one of the measures and then select a topic number based on those coherence values.
Files
In this example, we will use the Metacritic video games dataset.
You can find a link to the files on my GitHub repository: GitHub SolisAnalytics. The files in the repository will contain the entire code.
Understanding LDA (Latent Dirichlet Allocation)
Before we go over an example of how to implement LDA, let’s go over some basics about LDA.
At its core, LDA is a probabilistic model that assumes every document is a mixture of topics and a topic is a mixture of words. LDA aims to determine the mix of topics a document contains and the mix of words that define a topic. Below is a brief overview:
Documents and Words: A document is represented as a distribution over topics, and a topic is represented as a distribution over words in a corpus (text documents represented in a specific format).
Dirichlet Distribution: LDA is based on Dirichlet distribution for its math foundation. It assumes that K's potential topics are shared across a collection of documents. Each document is represented as a distribution over topics, and each topic is a distribution over words in a corpus.
Training and Inference: Given a set of documents, LDA goes backward to deduce the topics with the highest likelihood of generating the collection. This is done iteratively, adjusting its guesses about document-topic and topic-word distributions to maximize the likelihood of observing the documents.
With this in mind, let’s go over the example now.
Importing Libraries and Pre-Processing Text
First, import the libraries necessary to run the entire LDA workflow.

For simplicity purposes, we will only look at Nintendo DS game reviews. The rest of the DataFrame manipulation steps can be found in the GitHub repository.

Pre-Processing
We are ready to pre-process the reviews. We will create a function that will do the following: convert text to lowercase, tokenize into words, remove numbers and punctuation, remove stop words (based on SpaCy default list), lemmatize words (converting them into their root form), and remove words that are one character long.

Next, we will use the pre-processed text to create the dictionary and corpus. We will exclude words with a count of less than five and appear in more than 25% of texts. In practice, the outlier values will change depending on the business context.

Model Building and Coherence
We are ready to build an LDA model, but first, we must figure out how many topics to create and what parameters to use.
To start, we will briefly review two common coherence measures to select an optimal number of topics: u_mass and c_v.
U_mass: This measure is based on the difference in log probabilities of word pairs appearing in the same topic versus in separate topics. Values range from negative to positive. Higher values indicate better coherence.
C_v: This measure is based on a sliding window, one-set segmentation of top words, and an indirect confirmation measure that uses normalized pointwise mutual information (NPMI) and cosine similarity. Values range between o-1. Higher values indicate better coherence.
Now, we will go over two hyperparameters that influence the distribution of topics across documents and words across topics: Alpha (α) and Beta (β).
α: This parameter represents the distribution of topics in documents.
Low-value results in documents having a small number of dominant topics.
High-value results in documents having a more uniform distribution of topics.
Example: An alpha value of 0.01 means documents will have a few dominant topics, whereas an alpha of 1.0 will lead to more even topic distribution.
β: This parameter represents the distribution of words in topics.
Low value results in topics having a small number of dominant words
High-value results in topics having a more uniform distribution of all words in the vocabulary.
Example: A beta value of 0.01 means topics will have a few dominant words, whereas a beta of 1.0 will lead to topics having a more even distribution of words.
In our problem, we will use u_mass and alpha and beta of 0.01.

Let’s visualize the coherence values to determine which topic has the highest value.

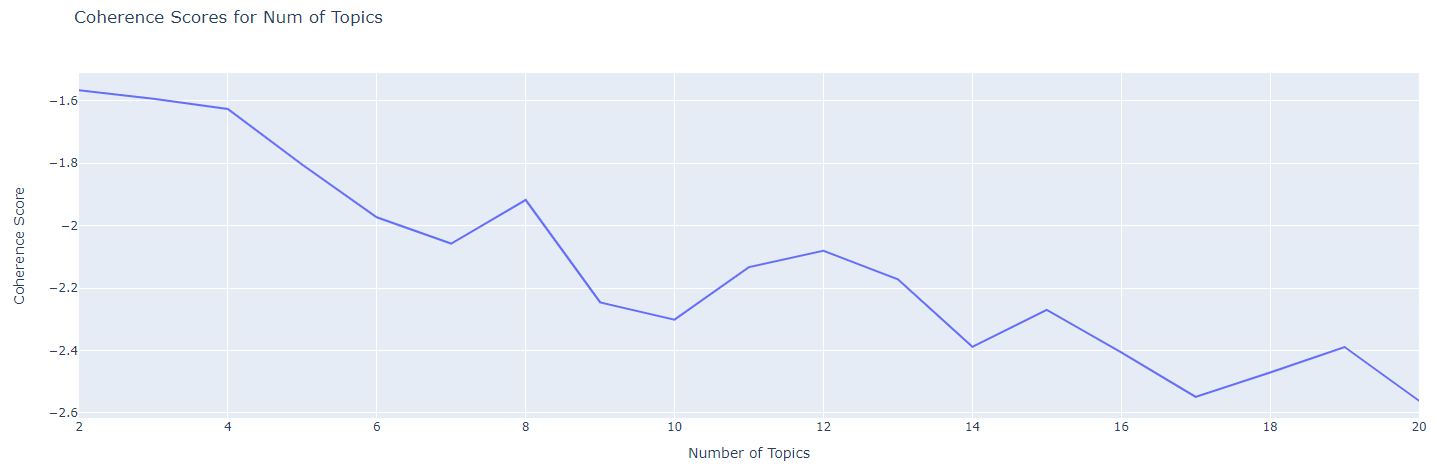
Figure shows coherence values. Higher values indicate better coherence for “u_mass” metric.
Coherence drops significantly after four topics. We will use four topics as our optimal value.
Optimal Model Results
Training LDA model with optimal number of topics.


Topic 1: friend, time, also, hero, one, level, puzzle, series, make, including
Topic 2: use, control, way, friend, pokemon, one, adventure, touch, different, character
Topic 3: character, screen, challenge, action, enemy, experience, unique, time, control, adventure
Topic 4: puzzle, screen, friend, unique, action, way, island, character, help, using
The four topics show some cohesiveness. The first topic references heroes, levels, and time. It could be related to an RPG. The second topic mentions Pokémon and adventure. The third topic has words such as challenge, unique, action, and enemy. The fourth topic is less coherent, indicating that three topics might have worked better. Another thing to note is that adding more domain-specific stopwords can help improve the meaning of the topics. Iteration is crucial when tackling unsupervised learning tasks because each pass can reveal something different.
Conclusion
LDA offers a structured method to uncover hidden thematic patterns in a text corpus. While the underlying mechanics are probabilistic, this article showcasing Python packages makes it approachable. The process doesn't end at the model building; visualizing topic coherence and selecting the optimal number of topics are crucial for meaningful results.
The journey through LDA, from preprocessing to coherence visualization, emphasizes the blend of art and science in NLP. It's not just about algorithms and models; it's about iterative refining and interpreting the results to uncover the underlying narrative of a corpus. Whether you're exploring user reviews, academic papers, or news articles, LDA offers a lens to distill vast textual data into discernible topics.